Sommaire
- 1 Extraction d’entités et callbot IA : transformer une conversation en données actionnables
- 2 De la reconnaissance vocale au NLP : la chaîne technique qui rend l’extraction fiable en production
- 3 Automatisation des appels : scénarios concrets où l’extraction d’entités fait gagner du temps (et de la qualité)
- 4 Concevoir un schéma d’entités robuste : du dictionnaire métier à l’analyse de données
- 5 Déploiement et conformité : sécuriser l’extraction d’entités dans les callbots IA sans freiner l’innovation
- 5.1 Intégrations : quand l’extraction devient une API, pas un fichier
- 5.2 Relier extraction et performance : du cockpit au pilotage
- 5.3 Quelles entités extraire en priorité dans un callbot IA ?
- 5.4 Quelle est la différence entre intention et extraction d’entités dans une interaction vocale ?
- 5.5 Comment améliorer la fiabilité de l’extraction quand la reconnaissance vocale se trompe ?
- 5.6 L’extraction d’entités est-elle compatible avec le RGPD ?
Dans un centre de contact, tout commence par une phrase au téléphone. « Je veux déplacer mon rendez-vous », « j’ai reçu une facture trop élevée », « mon Wi‑Fi ne marche plus ». Derrière ces mots, il y a des informations exploitables : un nom, une date, un numéro de contrat, un lieu, un produit, parfois un signal d’urgence. C’est précisément là que l’Extraction d’entités change la donne pour les Callbots IA : elle transforme une interaction vocale en données conversationnelles structurées, directement activables dans un CRM, un outil de ticketing ou un agenda. En 2026, l’enjeu n’est plus seulement de « comprendre » l’appelant, mais de capturer ce qui compte au bon format, sans faire répéter, sans formulaire, sans friction.
Cette extraction est la pièce qui relie la Reconnaissance vocale et le Traitement du langage naturel à l’Automatisation des appels réellement rentable. Un callbot peut répondre vite, mais s’il n’extrait pas les champs clés, l’appel finit quand même sur un bureau humain, ou pire : il se perd. À l’inverse, un callbot qui extrait proprement « date souhaitée », « motif », « identifiant », « adresse » et « niveau d’urgence » devient un standardiste infatigable… et un moteur d’Analyse de données pour piloter la relation client. La promesse est simple : moins de temps perdu, plus de qualité, et une traçabilité qui sécurise les décisions.
- L’Extraction d’entités convertit la parole en champs structurés (nom, date, produit, montant, etc.) utilisables par les systèmes métiers.
- Les Callbots IA performants combinent Reconnaissance vocale, Traitement du langage naturel et parfois *RAG* pour répondre juste et extraire fiable.
- La valeur vient autant de l’Automatisation des appels que de la qualité des données conversationnelles produites (reporting, conformité, amélioration continue).
- Les meilleurs résultats proviennent d’un design d’entités aligné sur les processus (CRM, ticketing, agenda), pas sur une liste théorique.
- La conformité (RGPD, journaux, consentement) se pilote plus facilement quand l’extraction est pensée « minimisation » dès le départ.
Extraction d’entités et callbot IA : transformer une conversation en données actionnables
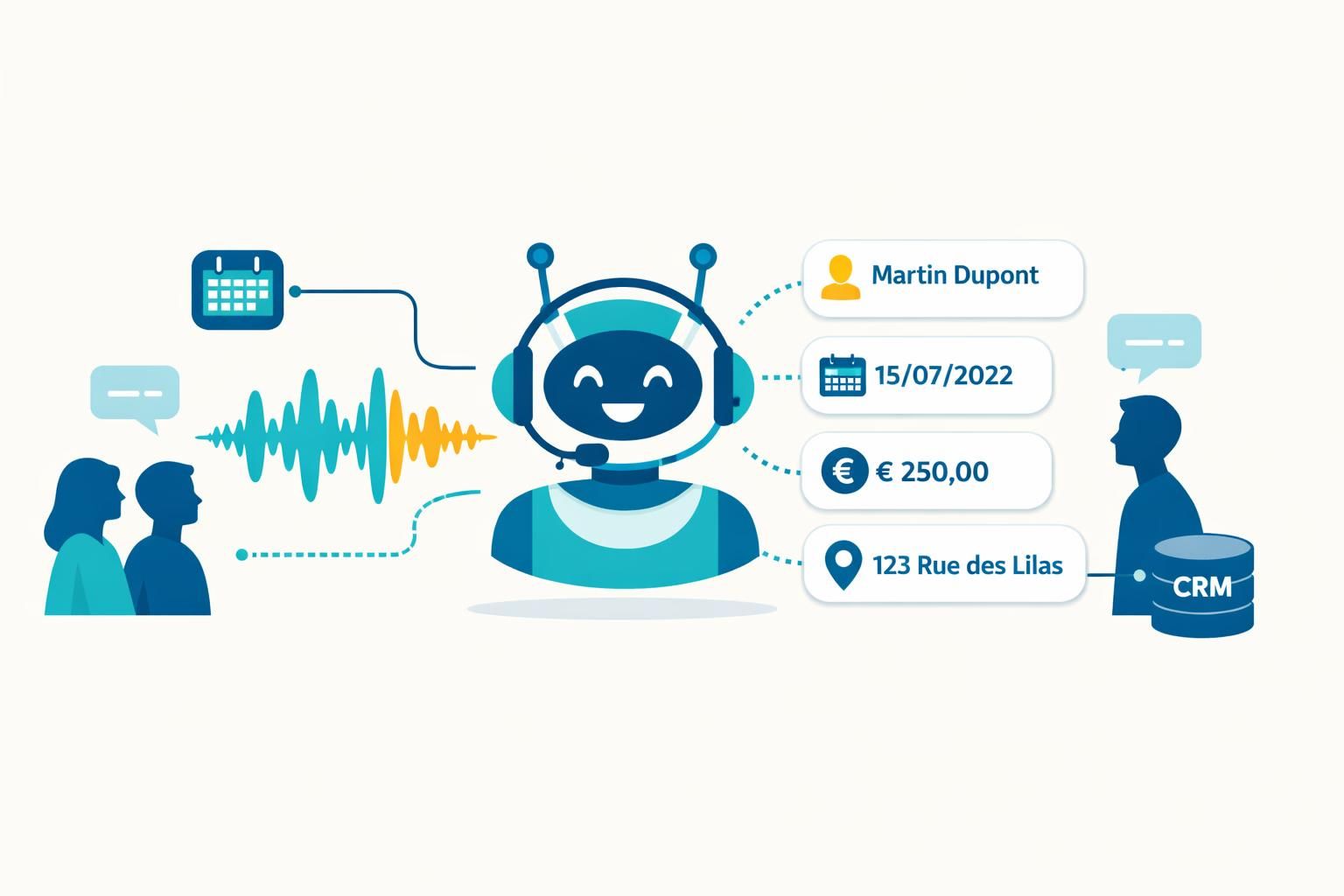
L’Extraction d’entités consiste à repérer, dans un flux de langage, des éléments qui ont une valeur métier et à les classer. Dans un appel, ces entités sont souvent des « morceaux » de vérité opérationnelle : une date (« demain matin »), une organisation (« la mutuelle X »), une zone géographique (« rue de la Paix à Paris »), une valeur monétaire (« 129 euros »), un produit (« box fibre ») ou encore un identifiant (« numéro de dossier », « plaque », « SIRET »). Le principe ressemble à un surligneur intelligent qui ne surligne pas au hasard : il surligne ce qui alimente un processus. Les explications généralistes sont disponibles, par exemple, via une définition pédagogique de l’extraction d’entités, mais un callbot impose des contraintes spécifiques : vitesse, bruit, accents, ambiguïtés et nécessité d’agir immédiatement.
Pour un décideur relation client, la nuance est essentielle : comprendre l’intention (« prendre rendez-vous ») ne suffit pas. Il faut extraire les paramètres (« quelle date », « quel site », « quel praticien », « quelle contrainte horaire ») et valider les incertitudes. Une entreprise fictive, “AtelierNord”, illustre bien le piège : son callbot répondait correctement à « je veux un rendez-vous », mais ne capturait pas l’adresse ni le type d’intervention. Résultat : un rappel humain systématique, donc une automatisation qui n’en est pas une. Après refonte des entités, le callbot a appris à demander « sur quel site » et à normaliser les créneaux (« lundi prochain » → date ISO). La différence se mesure en heures économisées, mais aussi en expérience client : moins d’allers-retours, moins de frustration.
Les types d’entités vraiment utiles au téléphone (et comment les cadrer)
Dans une conversation, les entités « classiques » (personnes, organisations, lieux, dates, quantités) restent centrales, mais l’entreprise gagne à ajouter des catégories métier. Un callbot d’assurance, par exemple, extrait un type de sinistre, un lieu d’incident, une date/heure, un numéro de contrat, parfois un niveau d’urgence détecté par le choix des mots et le ton. Une hotline IT extrait « application concernée », « message d’erreur », « site », « impact ». Ce n’est pas de la théorie : c’est de l’Extraction de texte orientée résultat.
Le cadrage commence par une question simple : quelles entités déclenchent une action ? Si « numéro de téléphone » ou « email » n’est jamais utilisé ensuite, mieux vaut ne pas le capturer, ou le demander uniquement en escalade. Cette logique sert la conformité et la sobriété. Elle rejoint d’ailleurs des approches prêtes à l’emploi dans les plateformes d’entreprise, par exemple via un modèle prédéfini d’extraction d’entités, utile pour accélérer les premières itérations avant de personnaliser.
À retenir
Un callbot qui extrait mal oblige à refaire le travail. Un callbot qui extrait bien devient un point d’entrée unique : il répond, il remplit les champs, et il déclenche le bon workflow sans rupture.
Tester AirAgent gratuitement · Sans engagement
De la reconnaissance vocale au NLP : la chaîne technique qui rend l’extraction fiable en production
Une Interaction vocale n’est pas un texte propre : c’est un signal audio imparfait, influencé par le bruit, le débit, la qualité du réseau et les habitudes de langage. La fiabilité de l’Extraction d’entités dans les Callbots IA dépend donc d’une chaîne technique cohérente, où chaque maillon réduit l’ambiguïté. Le premier maillon est la Reconnaissance vocale (*speech-to-text*). Si le système transcrit « quinze » au lieu de « vingt », l’extraction d’un montant ou d’un âge devient erronée, même si le modèle NLP est excellent. C’est pourquoi les projets sérieux suivent une logique d’optimisation conjointe : qualité audio, adaptation linguistique, gestion des hésitations (« euh »), et normalisation.
Ensuite vient le Traitement du langage naturel : identification de l’intention, extraction des entités, et résolution de références. Au téléphone, les références sont fréquentes : « le rendez-vous de mardi » (lequel ?), « le dossier que j’ai ouvert hier » (quel identifiant ?). Les modèles modernes s’appuient sur des mécanismes de contexte, mais la robustesse vient souvent de règles métiers simples : demander une confirmation quand la confiance est faible, reformuler les valeurs extraites, et recouper avec une base (ex. vérifier un code postal). Pour approfondir les briques qui composent un callbot, les pages sur la reconnaissance vocale appliquée aux callbots et sur le traitement du langage dans les callbots apportent des repères concrets.
Pourquoi les LLM améliorent l’extraction… mais ne remplacent pas le design
Les modèles de langage apportent une capacité de généralisation précieuse : ils reconnaissent qu’« j’ai déménagé » implique une mise à jour d’adresse, ou que « je pars en congés la semaine prochaine » contient une période. Cependant, en production, l’entreprise a besoin de garanties : formats stables, entités normalisées, contrôles. Un LLM peut deviner, mais il doit être encadré. C’est là que des stratégies hybrides s’imposent : extraction par modèle, validation par contraintes (regex, listes de valeurs, API), puis confirmation en conversation si nécessaire. L’objectif n’est pas de faire “brillant”, mais de faire juste et rejouable.
Un cas typique : la date « vendredi prochain ». Sans contexte, elle varie selon le jour d’appel. Un callbot efficace calcule la date précise, puis confirme : « Pour être certain, il s’agit bien du vendredi 12 ? ». Cette micro-confirmation évite une majorité d’erreurs silencieuses, qui coûtent plus cher qu’une question de 2 secondes. La même logique s’applique aux montants (« 130 ou 113 ? ») et aux adresses (épellation si besoin). Cet équilibre est l’un des marqueurs d’un callbot mature.
Encadré “Conseil d’expert”
Ne pas viser 100% d’extraction “sans question” dès le départ. Mieux vaut viser un taux de collecte stable (par exemple 85-90%) avec des confirmations ciblées, puis réduire progressivement les confirmations à mesure que l’Analyse de données révèle les ambiguïtés fréquentes.
Cette chaîne technique devient encore plus performante lorsque la réponse du callbot s’appuie sur des documents internes via une mémoire de type *RAG* : l’extraction fournit les clés (contrat, produit, site), et la recherche documentaire renvoie la procédure exacte. À ce stade, la question n’est plus « est-ce possible ? », mais « comment industrialiser ? ». C’est précisément l’objet de la section suivante : passer du prototype à l’Automatisation des appels à grande échelle.
Pour illustrer les enjeux de mise en œuvre, une vidéo aide à visualiser la différence entre transcription, compréhension et extraction dans un parcours téléphonique.
Automatisation des appels : scénarios concrets où l’extraction d’entités fait gagner du temps (et de la qualité)
Lorsqu’une entreprise déploie des Callbots IA, l’argument le plus visible est la disponibilité 24h/24. Pourtant, le gain le plus durable vient souvent d’ailleurs : la capacité à produire des données conversationnelles propres, immédiatement exploitables, sans ressaisie. Autrement dit, l’Extraction d’entités est le moteur discret qui rend l’Automatisation des appels mesurable. Il devient possible de traiter un volume important tout en améliorant la traçabilité. Un standard qui répond vite mais crée des tickets incomplets ne fait que déplacer le problème. À l’inverse, un callbot qui extrait précisément “qui”, “quoi”, “quand”, “où” et “comment” réduit le temps de traitement, y compris pour les demandes escaladées à un conseiller.
Le fil conducteur peut être celui d’un directeur relation client d’une PME, “CliniqueRivage”, confrontée à des pics d’appels saisonniers. Au départ, les appels “simples” saturent la ligne : déplacer un rendez-vous, demander un document, comprendre une facture. Le callbot prend l’appel, comprend l’intention, et surtout extrait les champs : identité, date souhaitée, service concerné, et motif. Même si l’appel finit transféré, le conseiller reçoit un dossier prérempli. C’est une différence tangible : au lieu de 3 minutes de qualification, il ne reste que 30 secondes de validation.
Cas d’usage qui fonctionnent le mieux (et pourquoi)
Les cas gagnants ont un point commun : ils reposent sur des entités bien définies et un processus clair derrière. Dans un service de santé au travail, l’appelant peut demander une “déclaration d’effectif” ou un “rendez-vous”. L’extraction vise alors des champs très concrets : nom d’entreprise, SIRET, période, effectif, coordonnées. Dans un fournisseur Wi‑Fi saisonnier, l’extraction porte sur le camping, le numéro de borne, le symptôme (“pas de réseau”), et l’horaire d’apparition. Dans une hotline d’aide sociale, l’entité la plus critique peut être le niveau d’urgence : il ne s’agit pas seulement de catégoriser, mais de déclencher la bonne escalade.
Pour les lecteurs qui veulent des exemples structurés de déploiement, un guide opérationnel sur les callbots IA donne une vision “terrain” des jalons et des KPI. Côté technique, les sujets d’intention et de routage se complètent bien avec la reconnaissance d’intention dans les callbots, car l’intention et les entités doivent être conçues ensemble.
Tableau comparatif : intention vs entités vs actions (lecture décideur)
| Demande au téléphone | Intention détectée | Entités à extraire (exemples) | Action automatisée possible |
|---|---|---|---|
| « Je veux décaler mon rendez-vous de mardi » | Gestion de rendez-vous | Date initiale, nouvelle date souhaitée, service, identité | Recherche de créneaux, replanification, SMS de confirmation |
| « Ma facture de 129 euros est anormale » | Contestations facture | Montant, période, référence facture, motif | Ouverture ticket avec champs, envoi du statut, rappel si seuil |
| « La box du camping ne capte plus depuis ce soir » | Support technique | Site, équipement, heure, symptôme, urgence | Diagnostic guidé, création incident, escalade technicien |
| « Je cherche une statistique sur la santé des dirigeants » | Accès information | Thème, population, période, indicateur | Recherche documentaire, synthèse orale, envoi rapport |
Le bénéfice est double : l’appelant obtient une réponse rapide, et l’entreprise obtient un enregistrement structuré. À partir de là, l’Analyse de données devient beaucoup plus simple : taux de demandes par motif, périodes de pics, taux d’échec d’extraction par entité. Cet éclairage alimente la gouvernance : quels processus simplifier, quelles informations rendre accessibles, quelles équipes renforcer aux bons moments. La section suivante détaille justement comment “industrialiser” cette logique, sans se perdre dans un projet trop lourd.
Découvrir AirAgent · Démo personnalisée offerte
Pour compléter la vision, une vidéo centrée sur l’automatisation des centres de contact permet de relier les concepts à des KPI concrets (temps moyen de traitement, taux de self-service, satisfaction).
Concevoir un schéma d’entités robuste : du dictionnaire métier à l’analyse de données
Un callbot peut être impressionnant en démonstration, mais la réalité d’un standard téléphonique se joue sur la cohérence des champs extraits. Le cœur du sujet est donc la conception d’un “schéma d’entités” : la liste des entités, leurs formats, leurs règles de validation et leurs usages. Cette étape n’est pas un détail technique, c’est une décision d’architecture de la relation client. Elle détermine la qualité des données conversationnelles, la pertinence des tableaux de bord et la capacité à automatiser sans dette opérationnelle. Autrement dit, c’est le moment où l’Extraction d’entités devient un actif durable.
Le point de départ est la cartographie des parcours : quels appels arrivent, quels sont les irritants, quelles informations sont systématiquement demandées par les agents. L’erreur courante consiste à créer trop d’entités “pour être complet”. Une approche plus fiable consiste à partir des actions : “créer un ticket”, “réserver”, “modifier une adresse”, “envoyer un document”, “qualifier une urgence”. Chaque action impose un jeu minimal de champs. Tout le reste est optionnel. Cette logique est aussi défendue dans des ressources qui abordent l’Extraction de texte et la structuration des données pour entraîner ou alimenter des modèles, comme les fondamentaux de l’extraction de données pour l’IA.
Normaliser pour éviter le chaos : formats, synonymes, et valeurs de référence
Au téléphone, les variantes sont infinies. Une même entité “date” peut être exprimée comme “demain”, “vendredi”, “le 12/03”, “dans deux semaines”. Une entité “lieu” peut inclure des raccourcis, des fautes, des hésitations. La robustesse vient de la normalisation : transformer les valeurs extraites en formats stables (date ISO, montant numérique, code postal à 5 chiffres). La normalisation doit être pensée comme une étape obligatoire, pas comme une option. Elle simplifie les intégrations, mais surtout elle rend l’Analyse de données fiable : sans format unique, les KPI deviennent des approximations.
Un exemple simple : “Paris”, “75”, “Paris 8e” et “75008” ne sont pas interchangeables pour un CRM. Un callbot mature extrait le texte, puis le mappe sur une référence (base de codes postaux, liste de sites, référentiel produit). S’il y a ambiguïté, il reformule. Cela peut sembler plus long, mais en pratique, c’est le meilleur moyen d’éviter les tickets erronés qui coûtent une reprise complète.
Mesurer la qualité d’extraction : la métrique qui change la discussion en comité de direction
Pour piloter, il faut des métriques lisibles : taux d’extraction par entité, taux de confirmation, taux d’échec et causes (bruit, vocabulaire, entité manquante). “AtelierNord” a par exemple découvert que l’entité “numéro de contrat” échouait surtout lorsque le client lisait trop vite. La solution n’a pas été “un meilleur modèle” immédiatement, mais un design conversationnel : demander de dicter en groupes de trois chiffres, puis reformuler. Résultat : baisse des erreurs et hausse de l’autonomie.
Dans une logique de gouvernance, ces indicateurs servent aussi la conformité. Extraire moins, mais mieux, réduit les risques. Pour cadrer la protection, la page sur RGPD et protection des données pour callbots aide à structurer les discussions avec le DPO, notamment sur la minimisation et la durée de conservation.
À retenir
Un bon schéma d’entités est un contrat entre le métier et la technique : il garantit que chaque conversation peut devenir une action, et que chaque action laisse une trace exploitable.
Déploiement et conformité : sécuriser l’extraction d’entités dans les callbots IA sans freiner l’innovation
Déployer l’Extraction d’entités dans des Callbots IA ne se limite pas à “brancher un modèle”. Il faut aligner la sécurité, la conformité et l’exploitation. En 2026, les décideurs attendent des systèmes auditables : qui a accédé à quoi, quelles données ont été conservées, et comment les erreurs sont gérées. La bonne nouvelle est que cette gouvernance se marie très bien avec une extraction bien conçue, car elle permet de ne capturer que l’essentiel, de journaliser proprement, et d’automatiser sans exposer des données inutiles.
Le premier réflexe consiste à distinguer trois catégories : les entités nécessaires à l’action immédiate (ex. date de rendez-vous), celles nécessaires à l’identification (ex. numéro de dossier), et celles “confort” (ex. commentaire libre). Les deux premières catégories peuvent être encadrées par des validations strictes. La troisième doit être traitée avec prudence, car le texte libre peut contenir des informations sensibles non sollicitées. Un callbot peut orienter la saisie : “décrivez le problème en évitant les données médicales”, par exemple. Ce n’est pas de la bureaucratie : c’est une manière pragmatique de protéger l’entreprise et l’appelant.
Intégrations : quand l’extraction devient une API, pas un fichier
Une extraction utile se connecte à l’écosystème : CRM, agenda, ticketing, ERP. La différence entre un projet “vitrine” et un projet rentable se joue ici. L’extraction doit alimenter des champs normalisés via API et récupérer des informations en retour (ex. vérifier un contrat). Les équipes techniques apprécient une architecture claire, décrite dans un schéma d’architecture conversationnelle, et complétée par une vision des briques télécom dans la téléphonie cloud pour callbots. Quand ces fondations sont en place, l’entreprise peut étendre les cas d’usage sans tout reconstruire.
Dans les ateliers de déploiement, un point revient souvent : le callbot doit pouvoir “échouer correctement”. Si l’entité est incertaine, il confirme. Si le système métier est indisponible, il bascule en création de ticket. Si la demande sort du périmètre, il transfère en fournissant déjà les entités extraites. Cette stratégie d’escalade rend l’expérience plus fluide, et protège la marque. L’appelant accepte un transfert quand il voit que le système a compris et préparé le terrain.
Relier extraction et performance : du cockpit au pilotage
Le tableau de bord n’est pas qu’un reporting. Il sert à prioriser les améliorations : quelles entités posent problème, quels motifs montent, quels créneaux saturent. C’est ici que l’Analyse de données issue des appels devient un outil managérial. Une direction relation client peut, par exemple, constater que les demandes de “changement d’adresse” augmentent dans une région précise et renforcer la communication proactive. Le callbot devient alors un capteur opérationnel, pas seulement un automate.
Pour ceux qui explorent aussi l’extraction de données au-delà du téléphone (documents, web, formulaires), des ressources sur le fonctionnement de l’extraction de données par IA ou les outils d’extraction de données par IA en 2026 permettent de comprendre les complémentarités. Le point clé est de garder une cohérence : la même entité “client” doit avoir le même identifiant dans tous les canaux, sinon l’entreprise fabrique des silos.
À ce stade, l’entreprise dispose d’une chaîne complète : capter la parole, comprendre, extraire, valider, agir, mesurer. La prochaine étape naturelle est de démarrer petit, mais avec une architecture extensible, afin de multiplier les cas d’usage sans rallonger les délais.
Essayer le callbot AirAgent · Configuration en 5 minutes
Quelles entités extraire en priorité dans un callbot IA ?
Les entités à prioriser sont celles qui déclenchent une action métier immédiate : identité (ou identifiant), date/heure, produit ou service concerné, lieu/site, motif normalisé, et éventuellement un niveau d’urgence. L’objectif est d’alimenter un CRM, un agenda ou un ticketing sans ressaisie, tout en minimisant les données collectées.
Quelle est la différence entre intention et extraction d’entités dans une interaction vocale ?
L’intention répond à la question « que veut faire l’appelant ? » (prendre rendez-vous, contester une facture). L’Extraction d’entités répond à « avec quelles informations concrètes ? » (date souhaitée, montant, référence, adresse). Dans les Callbots IA, les deux doivent être conçus ensemble pour obtenir une Automatisation des appels réellement opérationnelle.
Comment améliorer la fiabilité de l’extraction quand la reconnaissance vocale se trompe ?
Il faut combiner plusieurs leviers : améliorer l’audio (qualité télécom, réduction de bruit), adapter la Reconnaissance vocale au vocabulaire métier, normaliser les valeurs extraites (formats dates, montants), et ajouter des confirmations ciblées lorsque la confiance est faible. Une stratégie d’escalade (transfert avec champs préremplis) évite aussi les erreurs silencieuses.
L’extraction d’entités est-elle compatible avec le RGPD ?
Oui, à condition d’appliquer la minimisation (ne collecter que ce qui est nécessaire), de définir des durées de conservation, de sécuriser les flux (chiffrement, contrôle d’accès) et de journaliser de manière gouvernée. Une extraction bien cadrée réduit souvent le risque, car elle limite le texte libre et privilégie des champs structurés.