Sommaire
- 1 Speech-to-Text et callbot : comprendre la transcription vocale en centre de contact
- 2 Du traitement du signal à l’analyse du langage : comment un STT fiable se construit en 2026
- 3 STT vs SVI DTMF : pourquoi la transcription automatique change l’accueil téléphonique des callbots
- 4 Langues, accents et WER : sécuriser la reconnaissance vocale pour des callbots multilingues
- 5 Intégration en entreprise : sécurité, VoIP, CRM et pilotage de la transcription automatique des appels
- 6 Choisir un Speech-to-Text pour callbots : critères, solutions du marché et méthode de test
Saviez-vous qu’une grande partie de l’expérience d’un callbot se joue avant même la “réponse” ? Tout commence par la capacité à capter une voix souvent imparfaite (bruit de rue, micro de smartphone, accent, débit), à la transformer en texte exploitable, puis à alimenter un système de dialogue capable de décider quoi faire. C’est exactement le rôle du Speech-to-Text (STT) : une brique discrète, mais déterminante, qui conditionne la qualité de la communication automatisée. Quand la reconnaissance vocale est solide, l’interaction vocale paraît fluide ; lorsqu’elle trébuche, même la meilleure intelligence artificielle conversationnelle finit par donner l’impression de “ne pas écouter”.
En 2026, les centres de contact attendent du STT plus qu’une simple transcription automatique. Les décideurs veulent une compréhension robuste, une latence faible, une gestion fine des langues, et une intégration qui respecte la conformité. Le STT n’est plus un gadget d’accessibilité : il devient un levier opérationnel, capable de réduire l’attente, d’améliorer le routage, et de rendre chaque appel exploitable via l’analyse du langage. L’enjeu est clair : transformer un flux audio en données actionnables, sans sacrifier la satisfaction client. Et c’est précisément ce qui distingue un standard “qui répond” d’un accueil téléphonique “qui résout”.
- Le STT est la porte d’entrée d’un callbot : sans transcription fiable, le dialogue se dégrade rapidement.
- La performance se mesure avec le WER (taux d’erreur de mots), la latence, et la robustesse au bruit.
- Le traitement du signal (nettoyage audio) et l’analyse du langage (intention, entités) se complètent, ils ne se remplacent pas.
- Le langage naturel surpasse les menus DTMF pour la fluidité, à condition d’un STT calibré et d’un dialogue bien conçu.
- Les langues et accents changent la donne : certains idiomes atteignent des niveaux d’erreur très faibles, d’autres exigent une stratégie.
- La transcription automatique sert aussi à l’analytics, au coaching, et à la conformité, pas uniquement au bot.
Speech-to-Text et callbot : comprendre la transcription vocale en centre de contact
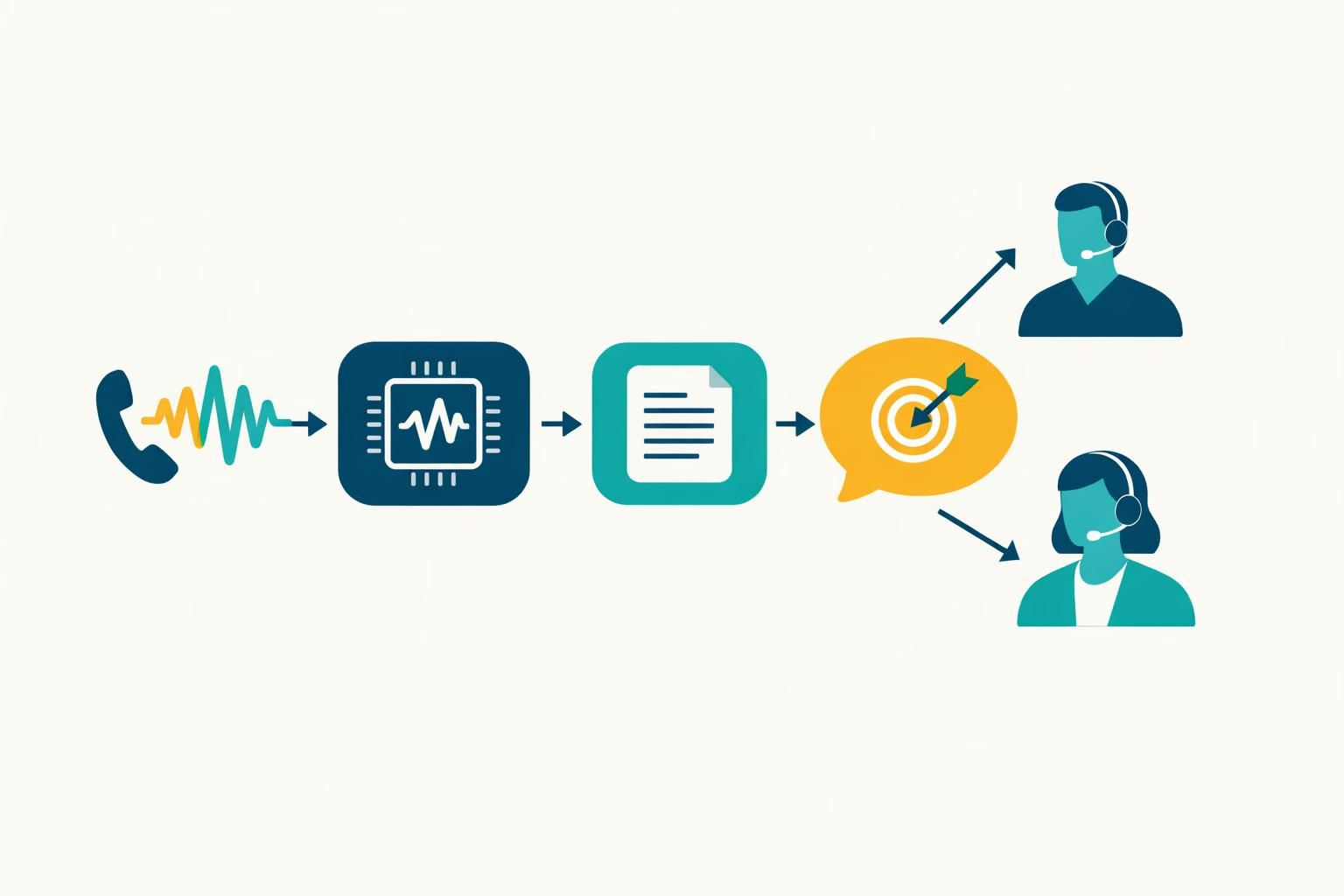
Le Speech-to-Text convertit la parole en texte. Dit comme cela, c’est simple. Dans un contexte de callbot, c’est surtout une chaîne de traitement qui doit être fiable en conditions réelles : combiné saturé, appels VoIP compressés, clients pressés, phrases incomplètes, et parfois une commande vocale lancée “au milieu” d’une phrase. L’objectif n’est pas d’obtenir une belle phrase à relire, mais un texte suffisamment juste pour alimenter un système de dialogue et déclencher l’action attendue : informer, orienter, authentifier, ou transférer.
Pour situer le STT dans l’écosystème, il se place entre le son et la compréhension. Le son arrive en flux, le STT produit des mots, puis l’analyse du langage (NLP/NLU) déduit une intention (“suivre une livraison”, “modifier un rendez-vous”) et extrait des éléments (numéro de dossier, date, ville). Pour une définition claire et accessible, la ressource explication du Speech-to-Text aide à poser les bases, notamment sur la reconnaissance automatique de la parole (ASR).
Dans une entreprise fictive mais réaliste, “Atelier Nord”, PME multi-sites, le standard reçoit des appels pour des horaires, des disponibilités, et des demandes SAV. Un SVI classique renvoie vers “tapez 1, tapez 2…”. Résultat : des clients quittent la ligne et rappellent. En basculant vers une interaction vocale en langage naturel, le client dit “je veux décaler mon rendez-vous” et le bot comprend. Mais cette fluidité n’existe que si la reconnaissance vocale transcrit correctement “décaler” et pas “décalerre” ou “déclarer”. Dans ce cas, l’intention bascule, et la confiance aussi.
Cette différence de philosophie est précisément celle entre DTMF et langage naturel. DTMF est robuste, mais rigide : l’utilisateur “obéit” au menu. Le langage naturel, lui, laisse l’utilisateur parler comme il parlerait à un conseiller. C’est pour cette modernisation que des solutions comme ViaSpeech se positionnent : serveur vocal interactif en langage naturel, couplé à la reconnaissance et à la synthèse. Pour comprendre leur logique fonctionnelle, la page FAQ ViaSpeech clarifie les cas d’usage (routage, horaires, modules de transcription, enregistrement, etc.).
Mais comment juger objectivement la qualité d’une transcription ? Un indicateur de référence est le WER (Word Error Rate), taux d’erreur de mots. Un WER inférieur ou égal à 5% correspond à une excellente précision, souvent atteignable dans des langues et conditions favorables. La nuance importante : un WER moyen peut masquer des erreurs critiques sur des mots-clés (noms propres, chiffres, villes). C’est pourquoi les pilotes STT sérieux évaluent aussi la précision sur “slots” métiers, par exemple la capacité à bien transcrire un numéro de contrat ou un code postal.
Enfin, le STT pour callbots ne se limite pas au temps réel. La transcription automatique en différé sert à relire, indexer, analyser les motifs d’insatisfaction, ou entraîner des modèles de détection (irritation, urgence, risque). Des ressources comme le lexique STT et transcription de voix permettent de distinguer clairement transcription “live” et “batch”, utile au pilotage opérationnel. Insight clé : quand le STT est traité comme un composant stratégique et pas comme une simple API, le centre de contact gagne en vitesse et en qualité de décision.
Tester AirAgent gratuitement · Sans engagement
Pour approfondir les différences entre voicebots et callbots en entreprise, un rappel utile se trouve sur la définition d’un voicebot en contexte professionnel, afin d’aligner vocabulaire, objectifs et périmètre projet.
Du traitement du signal à l’analyse du langage : comment un STT fiable se construit en 2026
Une bonne reconnaissance vocale n’est pas uniquement une question de modèle IA “plus gros”. Elle dépend d’une chaîne technique où le traitement du signal joue un rôle de premier plan. Avant même de “comprendre”, il faut rendre l’audio exploitable : réduction de bruit, normalisation du volume, suppression d’échos, détection de la parole (VAD), et parfois séparation des locuteurs. Sans ces briques, le STT travaille sur un matériau dégradé, et le WER augmente mécaniquement. Dans un centre d’appels, c’est comparable à une prise de notes dans une salle bruyante : même un excellent sténographe fera des erreurs si le son est mauvais.
Le flux téléphonique ajoute une contrainte : la bande passante audio et la compression. Les appels VoIP, courants en PME/ETI, encodent le son avec des codecs qui peuvent lisser des consonnes ou écraser des fréquences utiles. Cela explique pourquoi un STT “excellent en studio” peut décevoir au téléphone. Pour cadrer les enjeux d’intégration téléphonie, un détour par la téléphonie VoIP appliquée aux callbots en PME aide à anticiper les points d’attention (qualité audio, SIP, trunk, latence, routage).
Une fois le signal stabilisé, le STT effectue une conversion parole→texte. Le texte obtenu est ensuite exploité par un moteur de compréhension (NLU) : c’est là que l’analyse du langage extrait intention et entités, et que le système de dialogue décide d’une réponse. Les décideurs confondent parfois ces étapes : un STT ne “comprend” pas, il transcrit. À l’inverse, une NLU ne peut pas “rattraper” des erreurs de transcription trop fréquentes. Pour clarifier la place du NLP côté callbot, ce guide sur le NLP dans un callbot IA permet de distinguer les responsabilités de chaque couche.
La latence est l’autre métrique souvent négligée. Un callbot doit paraître naturel : si la réponse met deux secondes à démarrer après la fin de phrase, l’utilisateur coupe la parole, reformule, s’agace, et le dialogue se désynchronise. Un STT moderne en streaming envoie des hypothèses partielles (“partial transcripts”), qui permettent au bot d’anticiper. Cela demande une orchestration fine : si le bot parle trop tôt, il peut répondre à une phrase pas terminée. Un bon calibrage gère les silences, les hésitations et les reprises, comme un conseiller entraîné.
Le multilingue, enfin, est devenu central. Certains ensembles linguistiques atteignent des niveaux d’erreur très faibles, notamment en français, anglais, allemand, espagnol, italien ou néerlandais, quand l’audio est propre. D’autres langues affichent une précision plus variable, ce qui impose une stratégie : offrir un basculement vers un agent, ajuster les prompts, ou limiter certaines actions à confirmation explicite. Cela n’est pas un détail : dans des secteurs touristiques ou des réseaux retail en zone frontalière, la capacité à comprendre une demande en plusieurs langues se traduit directement en ventes et en désengorgement.
Pour les équipes techniques, les grands fournisseurs proposent des services STT industrialisés. Les pages Speech-to-Text sur Google Cloud et Speech-to-Text sur Azure donnent une vue concrète des options (temps réel, lots, adaptation, diarisation). Mais l’enjeu n’est pas seulement de “choisir un cloud” : c’est de garantir une qualité stable en production, sous charge, avec des exigences RGPD et des logs exploitables. Insight final : en 2026, le STT gagnant est celui qui combine excellence modèle, audio propre, et gouvernance de bout en bout.
Une démonstration vidéo permet souvent d’entendre la différence entre transcription brute et transcription optimisée pour le téléphone, notamment sur la gestion du bruit et des accents.
STT vs SVI DTMF : pourquoi la transcription automatique change l’accueil téléphonique des callbots
Le menu DTMF a longtemps été la colonne vertébrale de l’accueil téléphonique. Il a un mérite : il fonctionne dans presque tous les contextes, même avec une mauvaise qualité audio, parce qu’il repose sur des tonalités. Mais il impose un effort cognitif au client : écouter, mémoriser, naviguer, corriger. Dans une période où l’instantanéité est devenue la norme, cette friction pèse lourd. Le STT, lui, ouvre la voie à une commande vocale directe : “je veux suivre ma commande”, “j’ai perdu mon mot de passe”, “je souhaite parler à la facturation”. Ce changement ne relève pas du confort : il influe sur le taux de décroché utile, la durée moyenne d’appel, et la satisfaction.
Prenons un scénario concret. Une enseigne de services à domicile reçoit des appels le matin, avec des clients pressés. En DTMF, ils s’énervent au troisième menu. En langage naturel, ils posent leur question en une phrase. Le callbot transcrit, comprend, et soit répond, soit transfère au bon interlocuteur avec un contexte déjà posé. Résultat : moins de répétition et une prise en charge plus rapide. Cet “effet tunnel” est l’un des gains les plus tangibles de la communication automatisée.
La bascule vers le langage naturel exige toutefois une discipline de conception. Un callbot performant ne se contente pas d’écouter : il reformule et confirme quand il y a un risque métier. Exemple : pour une adresse ou un identifiant, le bot peut dire “Si le numéro est 482917, dites oui”. Cette confirmation réduit les erreurs transactionnelles, tout en gardant une expérience fluide. Là encore, la qualité de transcription automatique conditionne l’efficacité : si les chiffres sont mal reconnus, la confirmation devient trop fréquente et la conversation s’alourdit.
Pour aider à choisir un STT adapté aux callbots (téléphone, latence, langues, adaptation), la ressource bien choisir un STT pour les callbots fournit un angle décisionnel utile. À ce stade, une question revient souvent côté DSI : faut-il privilégier un moteur “généraliste” très bon partout, ou un moteur plus spécialisé avec adaptation métier ? En pratique, le meilleur compromis vient souvent d’une base robuste + une couche d’adaptation lexicale (noms de produits, acronymes internes, toponymes fréquents, etc.).
Pour objectiver cette décision, un tableau comparatif aide à mettre en face les critères qui comptent réellement en centre de contact.
| Critère | SVI DTMF (tonalités) | Callbot langage naturel (STT + NLU) |
|---|---|---|
| Expérience client | Navigation guidée, parfois longue | Dialogue direct, interaction vocale plus naturelle |
| Robustesse au bruit | Très élevée (tonalités) | Dépend de la qualité STT et du traitement du signal |
| Capacité à comprendre une demande complexe | Limitée à l’arborescence | Élevée via analyse du langage et intents |
| Routage intelligent | Basé sur le choix utilisateur | Basé sur intention, contexte, compétences |
| Évolutivité des scénarios | Réglages simples mais rigides | Plus flexible, nécessite gouvernance et tests |
| Exploitation des conversations | Faible (peu de données) | Forte via transcription automatique et analytics |
Une solution comme ViaSpeech illustre bien le passage du “menu” vers le dialogue : elle combine reconnaissance et synthèse, routage, et modules additionnels comme la transcription ou l’enregistrement, avec une configuration via interface web. Dans la réalité d’un service client, cette facilité de paramétrage accélère les itérations : changer un message d’attente, ajuster des horaires de transfert, ou activer une redirection devient un levier de pilotage quotidien, pas un projet IT. Insight de clôture : le langage naturel n’élimine pas la rigueur, il déplace l’effort vers la conception de dialogue et la qualité STT.
Une perspective complémentaire consiste à observer comment l’accueil téléphonique intelligent s’articule avec les contraintes de permanence, de débordement, et de transferts.
Langues, accents et WER : sécuriser la reconnaissance vocale pour des callbots multilingues
Le multilingue est souvent abordé comme une simple liste de langues “supportées”. Dans un centre de contact, la question utile est : quelle qualité réelle, dans quelles conditions, et avec quelle stratégie de secours ? Les niveaux de précision varient sensiblement selon les langues, les accents régionaux, et la disponibilité de données d’entraînement. Les environnements téléphoniques amplifient ces écarts, notamment quand l’appel transite par des réseaux mobiles instables.
Dans les meilleures conditions, certaines langues atteignent un WER très faible (excellente précision). Parmi elles figurent fréquemment le français, l’anglais, l’allemand, l’espagnol, l’italien ou le néerlandais, mais aussi plusieurs langues européennes et asiatiques selon les moteurs. À l’inverse, d’autres idiomes affichent une précision “bonne” à “modérée”, ce qui ne les rend pas inutilisables : cela signifie qu’il faut adapter le système de dialogue pour réduire les ambiguïtés, demander des confirmations plus intelligentes, et limiter les actions irréversibles.
Le piège classique est de traiter toutes les erreurs comme équivalentes. Or, dans un callbot, une erreur sur “oui/non” ou sur un chiffre est plus grave qu’une erreur sur un déterminant. Une stratégie robuste consiste à combiner : (1) des questions fermées sur les étapes sensibles, (2) des reformulations, (3) des validations côté back-office (format de numéro, cohérence date), et (4) un transfert “gracieux” vers un agent quand la confiance est basse. Cette notion de “confiance” (confidence score) est un signal clé fourni par la plupart des moteurs STT.
Un exemple parlant : un réseau de cliniques reçoit des appels en français et en arabe. Si le STT arabe est moins précis dans certaines configurations, le bot peut proposer une option de rappel par un agent bilingue dès que la probabilité d’erreur dépasse un seuil, plutôt que de forcer un dialogue qui s’éternise. Le client vit alors une expérience respectueuse, et l’entreprise évite des erreurs de rendez-vous. Dans cette logique, la communication automatisée n’est pas “tout ou rien” : elle orchestre l’automatisation et l’humain.
Les ressources généralistes peuvent aider à cadrer les critères de choix, mais il est préférable de les lire avec une grille “centre de contact”. Par exemple, ce point de vue sur le speech-to-text IA apporte un socle utile, à compléter avec des tests sur vos propres appels (bruit, débit, terminologie). Pour la partie “pratique” sur la retranscription audio et l’exploitation, cet article sur la retranscription audio éclaire les usages au-delà du bot, notamment l’analytique conversationnelle.
Enfin, le multilingue se gère aussi côté organisation. Les scripts d’accueil doivent être pensés pour éviter les phrases longues, réduire les homophonies, et orienter l’utilisateur vers des formulations “faciles à transcrire”. Ce n’est pas de la manipulation : c’est de l’ergonomie vocale. Une question rhétorique aide à trancher : vaut-il mieux proposer dix langues avec une expérience moyenne, ou trois langues avec une expérience excellente et des options de bascule propres ? Insight final : le multilingue performant est un produit, pas un paramètre.
Intégration en entreprise : sécurité, VoIP, CRM et pilotage de la transcription automatique des appels
Un STT réussi ne s’évalue pas seulement sur un bench technique. Il s’évalue sur sa capacité à s’intégrer au SI sans créer une dette de maintenance. En entreprise, le callbot s’insère entre la téléphonie (SIP, PBX, Asterisk) et les applicatifs (CRM, ticketing, ERP). Cette place charnière impose des exigences : continuité de service, monitoring, traçabilité, et contrôle des données. C’est là que le STT devient une brique d’architecture, pas un simple module.
Sur la partie téléphonie, les gains de productivité annoncés sont réels uniquement si l’intégration est propre : gestion des transferts, des files, des horaires, des débordements, et des messages. Un bon accueil vocal sait dire “nous vous rappelons” au lieu de laisser un client patienter indéfiniment. Pour cadrer ce sujet, l’accueil téléphonique IA montre comment l’automatisation peut absorber les demandes simples tout en gardant la main sur les cas sensibles. Dans des contextes de disponibilité étendue, la permanence téléphonique IA permet aussi de réfléchir à la continuité 24/7 sans épuiser les équipes.
L’intégration CRM est un accélérateur évident. La transcription automatique peut enrichir une fiche client (motif d’appel, intention, résumé, mots-clés), et surtout éviter la répétition : l’agent récupère le contexte dès la prise d’appel. Mais pour que cela marche, il faut définir quelles données sont stockées, combien de temps, et avec quelle granularité. Un “verbatim complet” peut être utile au coaching, mais inutile (et parfois risqué) pour la gestion courante. La ressource intégrer un callbot au CRM aide à poser les bonnes questions : champs, workflows, consentement, et exploitation.
Sur la sécurité, la question n’est pas seulement “où vont les données ?” mais “qui y accède et comment sont-elles protégées ?”. Les flux audio, les transcriptions, et les métadonnées (numéro appelant, durée, tags) doivent être gouvernés. Dans des secteurs réglementés, la transcription peut être chiffrée au repos, et l’accès restreint aux profils habilités. Une approche mature inclut aussi l’anonymisation automatique de certaines informations (numéro de carte, identifiant), selon le contexte. Cela exige un design : le STT fournit le texte, mais la politique de rétention et de masquage relève du projet.
La dimension pilotage mérite un point à part. Un dashboard utile suit : volumes d’appels, taux d’automatisation, taux de transfert, motifs d’échec, et indicateurs de compréhension (confiance STT, taux de reformulation). Dans l’entreprise “Atelier Nord”, le premier mois révèle que les appels “horaires” représentent 30% du flux, et que le bot résout 85% de ces demandes. Le deuxième mois, le bot échoue sur des noms de villes spécifiques. Une simple adaptation du vocabulaire et un ajustement du prompt vocal améliorent la qualité sans retoucher tout le SI. C’est ici que la promesse d’intelligence artificielle devient concrète : itérer vite, mesurer, corriger.
Découvrir AirAgent · Démo personnalisée offerte
Pour aller plus loin sur le composant STT lui-même, ce dossier sur la reconnaissance vocale des callbots complète l’angle “architecture” par des critères terrain (bruit, accents, scénarios, métriques). Insight final : l’intégration fait la différence entre un POC impressionnant et un dispositif opérationnel qui tient la charge.
Choisir un Speech-to-Text pour callbots : critères, solutions du marché et méthode de test
Le choix d’un moteur STT échoue souvent pour une raison simple : il est évalué sur de “bons” audios, puis déployé sur des appels difficiles. Une méthode persuasive consiste à inverser la logique : partir des pires cas réels (bruit, mobile, débit, colère), et vérifier que le STT reste suffisamment stable. Car un callbot ne gagne pas sur les appels faciles, il gagne sur les appels ordinaires. C’est là qu’un pilotage méthodique se transforme en avantage concurrentiel.
Les critères de décision se regroupent en quatre familles. Premièrement, la performance linguistique : WER global, précision sur entités métiers, gestion des chiffres, et reconnaissance des noms propres. Deuxièmement, la performance opérationnelle : latence, stabilité sous charge, et disponibilité. Troisièmement, l’adaptabilité : lexiques personnalisés, modèles de domaine, et capacité à apprendre des erreurs. Quatrièmement, la conformité et la gouvernance : localisation des données, rétention, auditabilité. Une ressource comme ce guide sur le speech-to-text aide à structurer cette grille, à condition de l’appliquer avec des appels téléphoniques, pas des dictées.
Sur le marché, plusieurs acteurs proposent des offres STT. Par exemple, Speech-to-Text chez ElevenLabs illustre une approche orientée IA vocale moderne. Les plateformes cloud généralistes offrent aussi une profondeur d’outillage. Le point déterminant n’est pas de choisir “le plus connu”, mais celui qui s’intègre le mieux à votre chaîne téléphonique, et qui produit une transcription réellement exploitable par votre système de dialogue.
Une méthode de test pragmatique repose sur un échantillon d’appels annotés. Il s’agit de comparer la transcription à une référence humaine, mais aussi de mesurer l’impact sur le dialogue : taux de compréhension d’intention, taux de confirmation, taux de transfert, et satisfaction post-appel. Si le STT améliore le WER de 2 points mais augmente les confirmations, le gain est peut-être nul. À l’inverse, un WER légèrement moins bon peut suffire si l’analyse du langage capte correctement l’intention et si les étapes sensibles sont sécurisées.
Un point souvent sous-estimé : le design conversationnel peut “aider” le STT. En posant des questions plus courtes, en évitant les ambiguïtés (“compte” vs “conte”), en demandant une réponse structurée (“dites votre code postal en cinq chiffres”), on augmente mécaniquement la fiabilité. C’est le même principe qu’un formulaire bien conçu sur un site : il réduit les erreurs utilisateur. Cette complémentarité entre traitement du signal, transcription, et dialogue rend l’ensemble plus robuste.
Enfin, le budget doit être traité avec rigueur. Le coût se calcule par minute audio, par canal, par options (diarisation, adaptation, logs), et par architecture (temps réel, lots). Mais le ROI se calcule sur des KPI : appels évités, temps agent réduit, transferts mieux qualifiés, et qualité de service. Pour cadrer les ordres de grandeur et les modèles de tarification, ce panorama des prix des callbots IA aide à raisonner au-delà du coût “API”. Insight final : le meilleur STT est celui qui fait baisser le coût par résolution, pas celui qui gagne un benchmark théorique.
Essayer le callbot AirAgent · Configuration en 5 minutes
Quel est le rôle exact du Speech-to-Text dans un callbot ?
Le Speech-to-Text transforme la voix en texte en temps réel afin d’alimenter l’analyse du langage et le système de dialogue. Sans transcription automatique fiable, le callbot comprend mal l’intention, multiplie les reformulations et transfère davantage, ce qui dégrade l’expérience et augmente le coût de traitement.
Comment évaluer la qualité d’une reconnaissance vocale au téléphone ?
La mesure la plus courante est le WER (taux d’erreur de mots), mais il faut aussi tester la précision sur des éléments métiers (chiffres, noms propres, références) et la latence. Les tests pertinents se font sur des appels réels, avec bruit, compression VoIP et diversité d’accents, car c’est là que les écarts apparaissent.
Le DTMF est-il encore utile face au langage naturel ?
Oui, dans certains cas. Le DTMF reste très robuste et peut servir de solution de repli quand la confiance STT est faible, ou pour des étapes ultra-sensibles. En pratique, les meilleurs dispositifs combinent langage naturel pour la fluidité et confirmations/alternatives pour sécuriser les actions critiques.
Quelles bonnes pratiques pour réduire les erreurs de transcription automatique ?
Améliorer la qualité audio (traitement du signal), adapter le vocabulaire (produits, acronymes, villes), concevoir des questions courtes et non ambiguës, et ajouter des confirmations intelligentes sur les informations sensibles. Le pilotage via tableaux de bord (taux de reformulation, motifs d’échec) accélère les itérations.