Sommaire
- 1 Architecture chatbot : composants du schéma technique d’un agent conversationnel moderne
- 2 Du chatbot à règles (ELIZA/Parry/GUS) à l’agent conversationnel : leçons concrètes pour une architecture chatbot robuste
- 3 Traitement du langage naturel, modèle de dialogue et machine learning : le moteur réel d’une architecture chatbot
- 4 Intégration API, sécurité et observabilité : industrialiser le schéma technique d’un agent conversationnel
- 5 Choisir une plateforme et concevoir le flux de conversation : méthode pragmatique pour décideurs en 2026
- 5.1 Conception conversationnelle : éviter les parcours “théoriques”
- 5.2 Plateformes no-code, low-code, code : arbitrer selon la criticité
- 5.3 Exemple de démarche en 4 temps, du pilote au déploiement
- 5.4 Quelle différence entre architecture chatbot et simple intégration d’un LLM ?
- 5.5 Comment choisir entre règles (type ELIZA) et machine learning ?
- 5.6 Pourquoi le modèle de dialogue est-il central dans un agent conversationnel ?
- 5.7 Quelles bonnes pratiques pour un callbot avec système de reconnaissance vocale ?
Un projet d’architecture chatbot ne se résume jamais à “brancher un modèle” et attendre que la magie opère. Derrière chaque réponse fluide, chaque relance pertinente et chaque bascule vers un conseiller, il existe un schéma technique précis où se coordonnent la collecte des signaux (texte, voix, contexte), le traitement du langage naturel, le modèle de dialogue, les règles métier, la sécurité et l’intégration API vers les outils du SI. En 2026, cette architecture devient un sujet de direction, car elle conditionne la qualité perçue par les clients, la conformité, et le ROI. Une même “brique IA” peut produire un assistant brillant dans un périmètre cadré, ou au contraire un robot hésitant si l’orchestration est mal pensée.
Pour rendre ces mécanismes concrets, l’article suit le fil d’une entreprise fictive, “Alpina Services”, qui reçoit des appels et messages sur des demandes répétitives (suivi de dossier, prise de rendez-vous, questions de facturation). Le défi n’est pas seulement de répondre : il faut identifier l’intention, vérifier l’identité, accéder à la bonne donnée, garder une trace, et savoir dire “stop” quand le risque augmente. C’est précisément là que le schéma technique d’un agent conversationnel fait la différence, qu’il s’agisse d’un chatbot web ou d’un callbot avec système de reconnaissance vocale. Le passage à une architecture robuste transforme un bot “démo” en véritable canal de service.
- Un agent conversationnel fiable s’appuie sur une chaîne bout-en-bout : entrée utilisateur → NLU/NLP → modèle de dialogue → outils → réponse.
- Le traitement du langage naturel ne suffit pas : mémoire, contexte, stratégies de clarification et garde-fous sont décisifs.
- Les approches “règles” (type ELIZA) restent utiles pour cadrer, tester et sécuriser des parcours critiques.
- Le machine learning apporte robustesse et adaptation, à condition d’être mesuré, observé et gouverné.
- Le cœur d’une bonne architecture chatbot est l’orchestrateur : il pilote le flux de conversation et les appels d’intégration API.
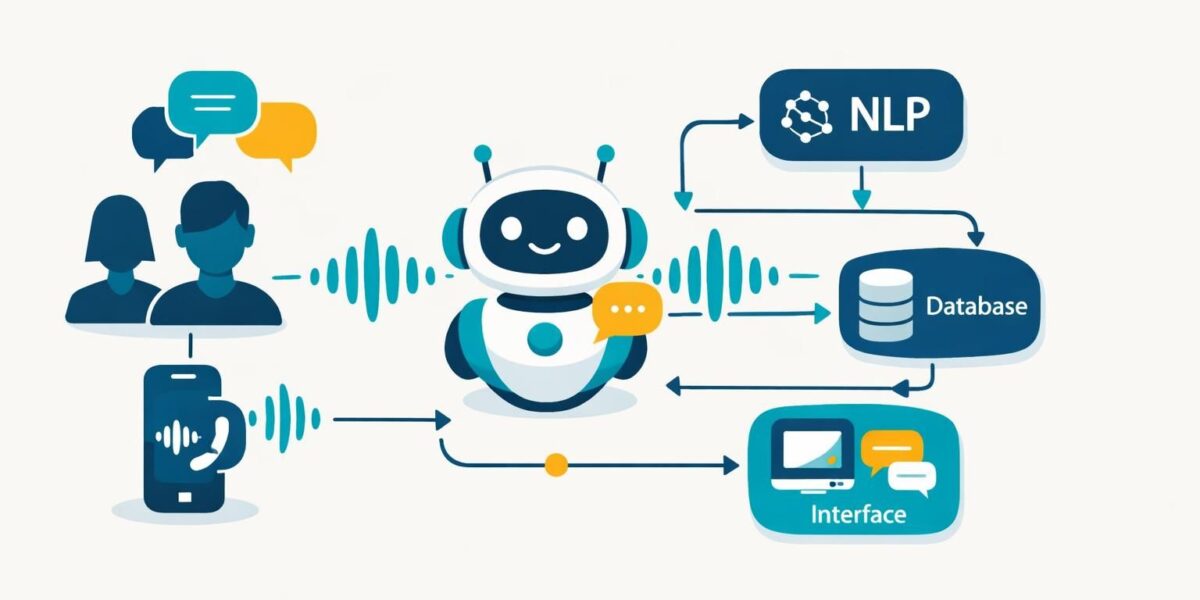
Architecture chatbot : composants du schéma technique d’un agent conversationnel moderne
Un schéma technique efficace commence par une idée simple : séparer ce qui “comprend”, ce qui “décide”, ce qui “agit”, et ce qui “répond”. Cette séparation évite l’effet boîte noire et permet d’améliorer chaque bloc sans casser le reste. Chez “Alpina Services”, le bot doit traiter des demandes de suivi de commande, de rendez-vous et de facturation. Ces cas d’usage imposent un enchaînement stable : identification, collecte d’informations minimales, consultation des systèmes internes, restitution claire, puis journalisation.
Le premier maillon est l’interface canal. Sur le web, un widget collecte le texte et des métadonnées (langue, page, heure). Au téléphone, un système de reconnaissance vocale convertit la parole en texte, tandis qu’une synthèse vocale restitue la réponse. Dans les deux cas, le canal doit ajouter du contexte (numéro appelant, identifiant session, type de client). Sans ce contexte, l’intelligence artificielle répond “comme si” chaque demande était isolée, ce qui dégrade l’expérience.
Vient ensuite le traitement du langage naturel, souvent découpé en deux niveaux. D’un côté, l’extraction : intention (suivre un dossier, déplacer un rendez-vous), entités (numéro de dossier, date). De l’autre, la normalisation : reformater une date “mardi après 17h” en créneau exploitable, corriger une faute, résoudre une ambiguïté. Cette normalisation est un détail en apparence, mais elle réduit drastiquement les échecs lors de l’intégration API vers CRM, ticketing ou agenda.
Le bloc central est le modèle de dialogue. Il ne s’agit pas seulement d’un “prompt”, mais d’un mécanisme de décision : que faire maintenant, que demander ensuite, quand confirmer, quand transférer. En pratique, le dialogue orchestre un flux de conversation avec des états. Par exemple : “collecte du numéro”, “vérification d’identité”, “appel au CRM”, “explication du statut”, “proposition d’action”. Ce modèle devient la colonne vertébrale qui transforme une réponse ponctuelle en parcours complet.
Enfin, la couche d’action relie l’agent aux outils : base de connaissance, CRM, ERP, paiement, agenda. Chaque appel doit être authentifié, journalisé, et protégé contre les entrées malveillantes. C’est là que l’architecture devient un sujet DSI. Pour approfondir des approches structurantes, une lecture utile consiste à parcourir des ressources sur les architectures d’agents et leurs workflows, par exemple un panorama des types d’agents et de leurs workflows, qui aide à clarifier le rôle de chaque composant.
Tester AirAgent gratuitement · Sans engagement
La suite logique consiste à descendre d’un niveau : comment un bot “règles” à la ELIZA a posé les bases, et pourquoi ces briques restent pertinentes pour sécuriser des conversations à enjeu.
Du chatbot à règles (ELIZA/Parry/GUS) à l’agent conversationnel : leçons concrètes pour une architecture chatbot robuste
Les projets pédagogiques autour d’ELIZA, Parry et GUS ne sont pas des curiosités historiques : ils offrent une grille de lecture très opérationnelle pour concevoir une architecture chatbot solide. ELIZA, créé entre 1964 et 1966, simulait un thérapeute en reformulant les phrases via reconnaissance de motifs et substitutions. Ce mécanisme met en évidence une réalité : l’utilisateur juge la qualité sur la cohérence locale (la prochaine phrase), bien avant de juger l’IA sur une “intelligence générale”. Une architecture moderne gagne donc à intégrer des réponses cadrées, même quand un LLM est disponible.
Dans un contexte entreprise, ELIZA inspire un module de “patterns” utile pour absorber les demandes fréquentes. Chez Alpina Services, un client écrit : “Mon colis n’est toujours pas arrivé”. Une réponse générative peut être pertinente, mais une réponse structurée l’est souvent davantage : demande d’identifiant, vérification du statut, proposition d’action. Le pattern sert ici de garde-fou et d’accélérateur.
Règles, regexp et détection de répétitions : des garde-fous très actuels
Une faiblesse classique des chatbots à règles est la fragilité de la ponctuation et des variantes. “What is your name?” n’est pas “What is your name ?” si la règle est trop stricte. La correction la plus saine consiste à normaliser en amont (espaces, apostrophes, casse), puis à passer sur des expressions régulières (*regexp*). Cette idée se transpose directement dans un bot 2026 : avant d’envoyer au moteur d’intelligence artificielle, un préprocesseur nettoie, détecte la langue, et repère les signaux d’incompréhension.
Autre apprentissage décisif : la répétition. Un utilisateur qui réitère “je veux parler à quelqu’un” ou reformule la même phrase est un signal d’échec de compréhension, pas un détail. Une stratégie robuste consiste à comparer les tours récents via une distance de Levenshtein (ou équivalent) pour repérer des formulations quasi identiques. Dans une architecture production, cela déclenche soit une clarification (“Souhaitez-vous un transfert ?”), soit une escalade directe. Résultat : moins d’irritation, et un meilleur taux de résolution.
Parry : variables affectives et stratégie de réponse, un prototype de pilotage
Parry ajoutait des variables affectives (peur, colère, méfiance) et sélectionnait une stratégie de réponse. Sans reprendre le concept tel quel, l’idée est très moderne : un bot doit adapter son style et ses choix aux signaux de l’échange. En centre de contact, la “colère” peut être approximée par des indices : répétitions, hausse de volume (côté voix), mots négatifs, interruptions. L’architecture gagne alors une couche “policy” : elle choisit une stratégie (apaiser, clarifier, transférer) avant même de générer la réponse.
Ce pilotage stratégique protège aussi l’entreprise. Quand le niveau de risque augmente (litige, paiement, données sensibles), l’agent conversationnel doit réduire l’improvisation et augmenter le contrôle : réponses validées, formulaires structurés, authentification renforcée, ou transfert humain. Ce n’est pas brider l’IA, c’est rendre le canal fiable.
GUS : leçons de dialogue orienté réservation, slots et hiérarchies
GUS, orienté organisation de voyage, introduit la logique de cadres et de *slots* (origine, destination, date, heure). C’est exactement ce dont un bot entreprise a besoin pour “remplir” une demande. Un exemple typique : “Un aller simple de Paris à Nice, après 17h mardi”. L’agent doit extraire plusieurs slots en un tour, gérer les réponses multiples et vérifier les ambiguïtés. La date est souvent hiérarchique : “mardi” doit devenir un jour précis selon le calendrier, puis un créneau selon la disponibilité. Quand cette logique est externalisée dans un fichier de configuration (comme ELIZA utilisait un script), les équipes métier peuvent faire évoluer le bot sans modifier le code cœur.
Pour des exemples de travaux structurés autour de ces TPs (agents basiques, ELIZA, Parry, GUS), la consultation d’un dépôt comme ce projet d’agent conversationnel en Python illustre bien comment documenter la démarche et relier décisions techniques et comportements observables. La transition naturelle est maintenant de relier ces fondations au cœur de l’architecture moderne : NLU, LLM, RAG et orchestration.
Lorsqu’un décideur veut passer du prototype à l’industrialisation, le point de bascule se joue souvent sur le choix des composants “comprendre/décider/agir”, et sur la capacité à les observer en production.
Traitement du langage naturel, modèle de dialogue et machine learning : le moteur réel d’une architecture chatbot
Dans une architecture chatbot moderne, la promesse “comprend le langage” doit être traduite en mécanismes vérifiables. Le traitement du langage naturel n’est pas un bloc unique : il mélange classification d’intentions, extraction d’entités, désambiguïsation, et parfois génération. Chez Alpina Services, une demande “Je veux décaler mon rendez-vous de demain” doit déclencher un parcours : retrouver le rendez-vous, proposer des créneaux, confirmer, puis écrire dans l’agenda. Sans un modèle de dialogue maîtrisé, même le meilleur moteur linguistique échoue.
NLU vs LLM : complémentarité, pas rivalité
Une NLU “classique” (intents + entités) offre de la prédictibilité. Un LLM apporte de la souplesse et une meilleure gestion des formulations. L’architecture la plus rentable en 2026 combine souvent les deux : la NLU verrouille les actions sensibles, tandis que le LLM gère la reformulation, l’empathie, et la FAQ évolutive. Cette approche hybride réduit les erreurs coûteuses, sans sacrifier la naturalité.
Le machine learning intervient à plusieurs niveaux. Il peut classifier des intentions à partir de données historiques, détecter des sentiments, prédire une probabilité d’escalade, ou recommander une réponse. Mais l’enjeu n’est pas d’empiler des modèles : il est de définir des seuils de confiance et des comportements. Si la confiance est faible, l’agent doit poser une question de clarification plutôt que “tenter une action”. C’est précisément le rôle de la politique de dialogue.
Le modèle de dialogue comme “chef d’orchestre” du flux de conversation
Un flux de conversation professionnel ressemble davantage à un processus métier qu’à une discussion libre. Il faut des confirmations, des étapes, des retours arrière. Un bon modèle de dialogue sait aussi gérer les interruptions : “Oui mais au fait, vous êtes ouverts le samedi ?”. L’orchestrateur doit décider : répondre brièvement, puis revenir au parcours initial, ou ouvrir un nouveau sujet. Sans cette capacité, l’expérience devient erratique et la durée d’appel augmente.
Dans les centres de contact, la voix ajoute une contrainte : la mémoire de travail de l’utilisateur est plus limitée qu’à l’écrit. Un callbot doit donc poser des questions courtes, proposer des choix limités, et répéter les éléments critiques. Cela influence directement le schéma technique : le module de formulation (NLG) doit être paramétrable selon le canal, et le système de reconnaissance vocale doit fournir des hypothèses (n-best) pour corriger les erreurs sans bloquer la conversation.
RAG et base de connaissances : éviter les réponses “plausibles mais fausses”
Quand un bot répond sur des politiques de retour, des tarifs, ou des conditions contractuelles, l’exactitude prime. Le *RAG* (retrieval-augmented generation) consiste à récupérer des passages pertinents dans une base documentaire, puis à générer la réponse à partir de ces éléments. L’architecture doit tracer ce qui a été utilisé pour répondre, afin de faciliter l’audit et la mise à jour. Pour une vision plus académique des composants d’un agent conversationnel, la lecture d’un document de synthèse comme ce papier sur l’architecture des agents conversationnels aide à comparer les patterns et à structurer un dossier d’architecture.
Un agent conversationnel n’est crédible que s’il sait quand il doit être créatif… et quand il doit être strictement factuel.
Ce socle “comprendre et décider” ne crée de valeur que s’il est branché au SI. Le prochain enjeu est donc l’intégration API, la sécurité et l’observabilité, là où se joue la mise en production.
Découvrir AirAgent · Démo personnalisée offerte
Intégration API, sécurité et observabilité : industrialiser le schéma technique d’un agent conversationnel
Un agent conversationnel devient réellement utile quand il peut agir : ouvrir un ticket, lire un statut, modifier un rendez-vous, déclencher un paiement, envoyer un SMS. Cela exige une intégration API propre, contractuelle, et testable. Chez Alpina Services, la première version du bot répondait bien aux questions générales, mais échouait dès qu’il fallait “faire”. Une fois les API CRM et agenda intégrées, le taux d’automatisation a progressé, car l’agent pouvait conclure le parcours au lieu de renvoyer vers un lien.
Contrats d’API et gestion des erreurs : le vrai confort utilisateur
La qualité perçue d’un bot dépend souvent de sa capacité à gérer les erreurs sans mettre l’utilisateur face à un mur. API en panne, timeouts, identifiant introuvable : chaque cas doit correspondre à une réponse claire et orientée solution. Le schéma technique doit donc inclure un module de résilience : retries, circuits breakers, et surtout messages adaptés. Dire “erreur 500” est une faute de design ; proposer “Un souci technique empêche l’accès au dossier, transfert immédiat ou rappel” est une expérience.
Les contrats d’API imposent aussi la normalisation des données. Une date, un numéro, un nom : l’agent doit produire des formats stricts. C’est là que les apprentissages de GUS (slots) redeviennent précieux. Le bot peut demander une reformulation ciblée : “Pour quelle date exactement ?” plutôt que “Je n’ai pas compris”. Cette précision réduit la durée de traitement et renforce la confiance.
Sécurité et conformité : authentification, données sensibles, traçabilité
Un bot qui lit des informations de compte doit vérifier l’identité. En messagerie, cela peut passer par un lien à usage unique. Au téléphone, une vérification par informations partielles (date de naissance, code envoyé par SMS) est fréquente. L’architecture doit segmenter les données : ce que le bot peut voir, ce qu’il peut dire, et ce qu’il peut modifier. Une règle simple convainc rapidement un décideur : toute action “irréversible” doit exiger une confirmation explicite et être loguée.
La traçabilité ne sert pas qu’à la conformité ; elle sert à l’amélioration continue. Chaque tour de dialogue doit laisser une trace : intention détectée, confiance, API appelées, latence, issue du parcours. Sans cela, impossible de piloter le ROI. En 2026, l’observabilité devient un différenciant : un bot “performant” est un bot mesuré, pas un bot “impressionnant en démo”.
Tableau comparatif : règles, NLU, LLM, hybride, et impact SI
| Approche | Forces principales | Limites typiques | Quand la privilégier | Impact sur l’intégration API |
|---|---|---|---|---|
| Règles (type ELIZA) | Contrôle fort, réponses cadrées, déploiement rapide sur un périmètre étroit | Fragile aux variantes, faible couverture, maintenance manuelle | FAQ stable, pré-qualification simple, parcours à risque | Faible complexité, mais nécessite une normalisation stricte en amont |
| NLU intents/entités | Prédictible, bon pour l’action, compatible avec des parcours “slots” | Besoin de données d’entraînement, couverture limitée si le vocabulaire évolue | Processus métier répétitifs, automatisation structurée | Très bon alignement : intents → endpoints, entités → paramètres |
| LLM génératif | Souplesse, compréhension contextuelle, ton naturel | Risque d’hallucination, contrôle plus délicat, coût/latence | Support généraliste, reformulation, réponses “explicatives” | Doit être encadré par des outils et politiques, sinon actions risquées |
| Hybride (NLU + LLM + RAG) | Meilleur compromis : contrôle + naturel + précision documentaire | Architecture plus exigeante, nécessite gouvernance et monitoring | Service client multicanal, callbot, volumétrie importante | Excellent : orchestration claire des appels, audit des décisions |
À retenir : la mise en production ne dépend pas seulement du modèle, mais de la solidité de la couche d’actions, de sécurité et d’observabilité. Un bot qui “parle bien” mais ne sait pas agir de manière sûre coûte plus qu’il ne rapporte.
La dernière étape consiste à transformer cette architecture en choix de plateforme et en méthode de déploiement, pour accélérer sans perdre le contrôle.
Choisir une plateforme et concevoir le flux de conversation : méthode pragmatique pour décideurs en 2026
Une fois le schéma technique clarifié, la question devient : construire, assembler, ou acheter ? En pratique, un décideur relation client cherche un time-to-value rapide, tandis que la DSI cherche la maîtrise des risques. Une plateforme bien choisie permet d’orchestrer le flux de conversation, de gérer le multicanal, et de simplifier l’intégration API sans enfermer l’entreprise. Ce compromis est atteignable si la méthode de conception est rigoureuse.
Conception conversationnelle : éviter les parcours “théoriques”
Le meilleur test d’un bot reste une demande réelle, exprimée avec hésitations. Chez Alpina Services, une cliente dit au téléphone : “Euh… j’ai reçu une facture mais je comprends pas, c’est plus cher que d’habitude”. Un parcours efficace ne commence pas par des menus, mais par une clarification guidée : “Souhaitez-vous vérifier le détail ou contester le montant ?”. La conception doit limiter la charge cognitive, surtout en voix, et proposer des sorties de secours à tout moment.
Pour approfondir la conception de bots orientés expérience, certaines ressources structurent bien les bonnes pratiques, par exemple un guide de conception chatbot qui insiste sur la scénarisation, la personnalité et la robustesse des dialogues. En complément, une synthèse plus “cadre méthodo” comme les principes IBM sur le chatbot design aide à aligner UX, objectifs métier et contraintes techniques.
Plateformes no-code, low-code, code : arbitrer selon la criticité
Les plateformes no-code accélèrent la mise en place de parcours simples et la mise en production multicanal. Les frameworks code permettent une personnalisation totale, au prix d’un effort d’intégration. Une approche persuasive pour arbitrer consiste à classer les cas d’usage par criticité : les demandes à faible risque (horaires, procédures) peuvent être traitées plus librement ; les demandes sensibles (modification d’adresse, paiement, résiliation) exigent davantage de contrôle, donc une orchestration et des validations plus strictes.
Pour donner un repère concret, il est utile de comparer les plateformes sur quelques axes réellement décisionnels : capacité RAG, gestion des connecteurs, pilotage des versions, et support du français en production. Une bonne sélection réduit le coût total, non pas parce que le prix licence est faible, mais parce que les cycles de correction et d’amélioration deviennent plus rapides.
Exemple de démarche en 4 temps, du pilote au déploiement
- Cadrer un périmètre mesurable : 10 intentions, 3 parcours actionnables, un canal prioritaire.
- Instrumenter dès le départ : taux de compréhension, taux d’automatisation, latence API, raisons de transfert.
- Sécuriser les actions : authentification, confirmations, droits, journaux.
- Industrialiser : tests de non-régression, gestion de versions, revue de prompts/règles, gouvernance métier.
Cette méthode évite l’erreur la plus courante : déployer un bot “large” mais peu profond. Un bot étroit mais actionnable crée rapidement de la confiance, puis s’étend par itérations.
Conseil d’expert : avant d’ajouter de nouvelles intentions, améliorer la gestion des échecs. Un seul bon mécanisme de clarification et de transfert bien déclenché peut augmenter la satisfaction plus vite que 20 nouvelles réponses.
Pour relier ces enjeux au canal voix, utile lorsque l’objectif est de réduire la charge du standard, un détour par les différences entre bot vocal, chatbots et assistants éclaire les contraintes spécifiques du téléphone et aide à aligner architecture et expérience.
Essayer le callbot AirAgent · Configuration en 5 minutes
Quelle différence entre architecture chatbot et simple intégration d’un LLM ?
Une architecture chatbot décrit l’ensemble du schéma technique : canal (web/téléphone), traitement du langage naturel, modèle de dialogue, orchestration du flux de conversation, intégration API aux outils, sécurité et observabilité. Intégrer un LLM seul améliore la formulation, mais ne garantit ni la capacité à agir dans le SI, ni la conformité, ni la robustesse face aux erreurs.
Comment choisir entre règles (type ELIZA) et machine learning ?
Les règles restent pertinentes pour des parcours critiques et des réponses strictement contrôlées. Le machine learning est utile pour mieux couvrir la diversité des formulations et améliorer la compréhension. En pratique, une approche hybride fonctionne très bien : règles et NLU pour piloter les actions, LLM pour la reformulation et l’assistance, avec des seuils de confiance et un transfert humain quand le risque augmente.
Pourquoi le modèle de dialogue est-il central dans un agent conversationnel ?
Le modèle de dialogue décide de la prochaine action : poser une question, confirmer, appeler une API, expliquer un résultat, ou transférer. Sans ce pilotage, le bot peut comprendre une demande mais échouer à la résoudre. C’est aussi le composant qui gère les interruptions, les retours arrière et les clarifications, donc la fluidité réelle du flux de conversation.
Quelles bonnes pratiques pour un callbot avec système de reconnaissance vocale ?
En voix, il faut des phrases courtes, des confirmations explicites et une tolérance aux erreurs. Techniquement, le système de reconnaissance vocale doit remonter des hypothèses multiples quand c’est possible, et l’architecture doit prévoir des stratégies de reprise (reformuler, épeler, proposer un SMS, transférer). L’observabilité (taux de silence, interruptions, incompréhensions) est essentielle pour itérer rapidement.


