Sommaire
- 1 A/B Testing callbot : comprendre le levier d’Optimisation des Scénarios Conversationnels
- 2 Mesurer l’Expérience Utilisateur et le Taux de Conversion : métriques utiles pour l’A/B Testing Callbot
- 3 Concevoir des variantes de Scénarios Conversationnels : micro-changements, grands effets sur l’Interaction Vocale
- 4 Analyse de Données et biais : sécuriser l’A/B Testing sur un Callbot en production
- 5 Industrialiser l’Optimisation : gouvernance, cycles d’Automatisation et Conseil d’expert
- 5.1 Conseil d’expert : bâtir un “pipeline” de tests sans épuiser les équipes
- 5.2 Quels Scénarios Conversationnels tester en priorité sur un callbot ?
- 5.3 Comment éviter que l’A/B Testing dégrade l’Expérience Utilisateur ?
- 5.4 Quelle différence entre Optimisation de script et amélioration du modèle d’Intelligence Artificielle ?
- 5.5 Combien de temps faut-il pour obtenir des résultats fiables en A/B Testing sur un Callbot ?
En bref
- A/B Testing appliqué au Callbot : une méthode pragmatique pour améliorer les Scénarios Conversationnels sans refonte globale.
- Les gains les plus rapides viennent souvent de micro-variantes sur l’Interaction Vocale : salutation, rythme, choix des mots, gestion des silences, confirmation.
- Le succès dépend d’une Analyse de Données solide : définition d’un objectif, instrumentation, segmentation, et lecture des résultats par intention.
- Une Optimisation utile protège l’Expérience Utilisateur : réduire l’effort, clarifier, rassurer, et mieux escalader vers un humain.
- L’Intelligence Artificielle aide, mais ne remplace pas la discipline expérimentale : hypothèses, échantillons, biais, et validation.
- Pour industrialiser, il faut un cadre : gouvernance, cycles d’essais, et bibliothèque de variantes réutilisables.
Un callbot performant ne se juge pas à la beauté d’un script, mais à sa capacité à faire avancer un appel vers une résolution claire. En 2026, les centres de contact qui réussissent l’Automatisation ne misent plus sur un “grand scénario” figé : ils adoptent une logique d’itération rapide, pilotée par l’Analyse de Données. C’est précisément là que l’A/B Testing devient une arme décisive : comparer deux versions d’un même embranchement, mesurer l’effet sur le Taux de Conversion (prise de rendez-vous, qualification, paiement, suivi), puis généraliser ce qui fonctionne. La nuance est essentielle : sur la voix, tout se joue dans des détails que l’écrit ne révèle pas. Une formulation plus courte, une question fermée plutôt qu’ouverte, ou une confirmation explicite peuvent réduire l’hésitation et limiter les abandons.
Pour rendre le sujet concret, imaginons une PME de services à domicile, “Atelier Nova”, qui reçoit chaque jour des appels pour planifier des interventions. Son Callbot gère déjà une partie des demandes, mais les échecs se concentrent sur un moment précis : la collecte d’adresse et la proposition de créneau. Sans changer d’architecture, l’équipe teste des variantes sur les Scénarios Conversationnels, observe les écarts, et améliore progressivement l’Expérience Utilisateur. L’objectif n’est pas de “faire parler” l’assistant, mais de l’orienter vers l’action, avec une Interaction Vocale simple, rassurante et efficace.
A/B Testing callbot : comprendre le levier d’Optimisation des Scénarios Conversationnels
Dans un centre d’appels, l’A/B Testing sur un Callbot consiste à exposer des appelants à deux variantes d’un même passage conversationnel, puis à comparer les résultats selon un indicateur métier. La logique est comparable à l’optimisation d’un parcours en boutique : si deux vendeurs peuvent prononcer des phrases différentes au même moment, laquelle mène le plus souvent à une décision ? Sur la voix, cette démarche est encore plus puissante, car une phrase “à peu près” compréhensible peut suffire à faire décrocher un appelant pressé.
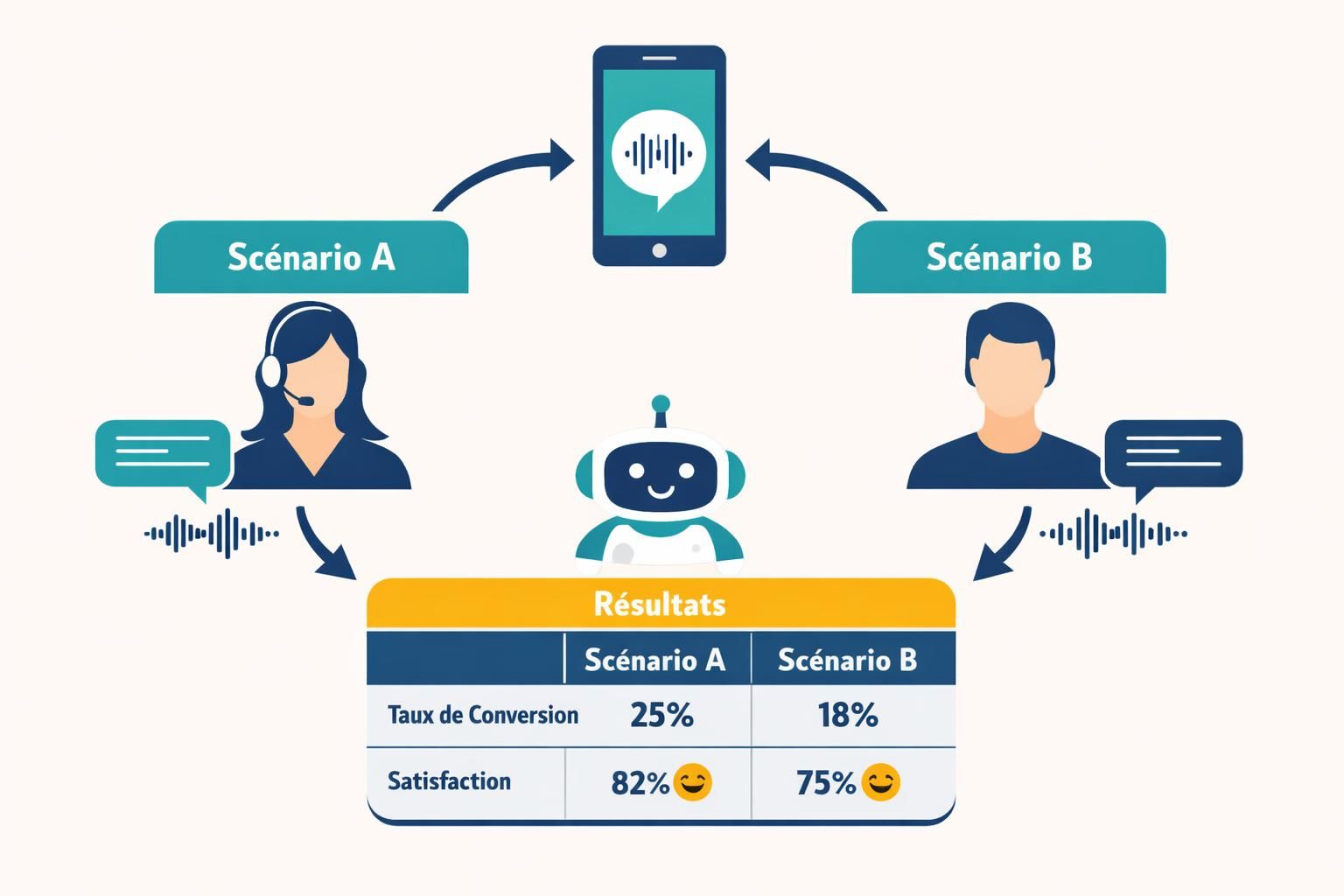
La clé est de penser “hypothèse” plutôt que “préférence”. Une équipe peut croire qu’une formulation polie augmente l’adhésion ; une autre suppose qu’une formulation directe réduit le temps d’appel. L’Analyse de Données tranche, à condition de définir une métrique principale claire. Pour “Atelier Nova”, la métrique prioritaire n’est pas le temps moyen, mais le Taux de Conversion vers un rendez-vous confirmé. Un callbot qui va vite mais perd des demandes au passage ne rend pas service.
Une difficulté fréquente vient d’un malentendu : tester “tout le scénario” en une fois. En pratique, l’Optimisation est plus fiable quand elle isole une variable. Par exemple, ne modifier que la manière de demander l’adresse, sans toucher à la reconnaissance des dates. Cela permet d’expliquer la cause d’un changement de performance. L’Intelligence Artificielle (ASR, NLU, orchestration) peut varier les sorties, mais l’expérimentation doit rester contrôlée.
Les variantes typiques en Interaction Vocale incluent la structure des questions, la longueur des phrases, la présence d’exemples (“Dites ‘mardi matin’”), ou l’explicitation des options. Sur le terrain, un callbot qui dit “Quel créneau vous arrange ?” obtient souvent des réponses floues, alors que “Préférez-vous mardi ou mercredi ?” cadre davantage. Cela ne rend pas l’expérience plus rigide ; cela réduit l’effort cognitif. L’insight final : un bon test A/B n’oppose pas deux styles, il vérifie quel niveau de guidage produit la meilleure progression.
Essayer le callbot AirAgent · Configuration en 5 minutes
Avant d’aller plus loin, une représentation visuelle aide à ancrer les notions : un flux d’appels, deux chemins, une mesure, puis une décision de déploiement.
Mesurer l’Expérience Utilisateur et le Taux de Conversion : métriques utiles pour l’A/B Testing Callbot
Les métriques font ou défont un programme d’A/B Testing. Trop souvent, l’entreprise mesure ce qui est facile (durée d’appel) plutôt que ce qui est utile (résolution, confiance, intention atteinte). Pour “Atelier Nova”, l’expérience montre qu’un rendez-vous pris en 2 minutes mais annulé ensuite coûte plus cher qu’un rendez-vous pris en 3 minutes avec une adresse validée. Les indicateurs doivent donc refléter la qualité, pas seulement la vitesse.
Un cadre efficace consiste à distinguer trois niveaux. D’abord les métriques de parcours : taux d’abandon, taux d’escalade vers un agent, répétitions (“pardon ?”), et nombre de tours de parole. Ensuite les métriques métier : Taux de Conversion vers une action (RDV, paiement, ouverture de dossier), taux de collecte de champs (adresse complète, numéro de contrat), et taux de résolution au premier contact. Enfin les métriques d’Expérience Utilisateur : satisfaction post-appel, effort perçu, et consentement à être rappelé.
Pour rendre ces mesures comparables entre variantes, il faut instrumenter correctement chaque étape du scénario : quel prompt a été joué, quelle intention a été détectée, et quel résultat a été atteint. Sans cette granularité, une variante peut sembler meilleure globalement, alors qu’elle dégrade une intention critique (par exemple la gestion d’une urgence). L’Analyse de Données doit donc être segmentée par motif d’appel, par source (numéro public vs campagnes), et par contexte (heures de pointe). Un callbot peut performer très bien la nuit, mais moins bien quand le bruit ambiant augmente en journée.
Tableau comparatif : choisir les bons KPI pour l’Optimisation des Scénarios Conversationnels
Le tableau suivant aide à relier une métrique à une décision. Il ne s’agit pas d’accumuler des chiffres, mais de savoir quoi corriger quand un test “gagne” ou “perd”.
| Indicateur | Ce que cela révèle | Décision d’Optimisation typique | Risque si mal interprété |
|---|---|---|---|
| Taux de Conversion (objectif atteint) | Efficacité du scénario sur la valeur métier | Généraliser la variante gagnante sur l’intention testée | Ignorer un effet négatif sur d’autres intentions |
| Taux d’abandon | Friction, incompréhension, manque de confiance | Raccourcir les prompts, clarifier la question, ajouter un exemple | Confondre abandon et transfert volontaire vers un humain |
| Taux d’escalade | Limites de l’Automatisation ou besoin d’humain | Améliorer la détection d’intention ou l’étape de triage | Réduire l’escalade au détriment de l’Expérience Utilisateur |
| Nombre de tours de parole | Complexité et effort conversationnel | Passer à des questions fermées ou confirmer plus tôt | Optimiser “trop” et rendre l’échange abrupt |
| Score de satisfaction post-appel | Perception globale, confiance, clarté | Renforcer les formulations rassurantes et l’explication du prochain pas | Score biaisé si seuls les mécontents répondent |
Un point souvent sous-estimé concerne la stabilité statistique. Sur un callbot, la variabilité est forte : accents, bruit, débit de parole, et qualité réseau. Il est donc judicieux de définir un seuil minimal de volume avant de conclure. L’insight final : une métrique n’est actionnable que si elle se rattache à un levier précis du scénario.
Une fois les indicateurs clarifiés, l’étape suivante consiste à concevoir des variantes qui testent réellement une hypothèse, plutôt que des changements cosmétiques.
Concevoir des variantes de Scénarios Conversationnels : micro-changements, grands effets sur l’Interaction Vocale
Un scénario vocal ressemble à un couloir : s’il est mal éclairé, l’utilisateur ralentit, hésite, puis rebrousse chemin. Les meilleurs tests A/B ne changent pas la destination, ils améliorent l’éclairage. Dans “Atelier Nova”, une simple reformulation a eu un effet mesurable : remplacer “Pouvez-vous me donner votre adresse complète ?” par “Dites d’abord le numéro et la rue, puis la ville” a augmenté le taux de collecte correcte. Pourquoi ? Parce que la consigne découpe la tâche et réduit la charge mentale.
Les variantes pertinentes se construisent autour d’un point de friction observé. Un callbot peut comprendre l’intention “prendre rendez-vous”, mais échouer à cause d’une étape administrative. C’est là que l’Optimisation des Scénarios Conversationnels devient très concrète : guider l’appelant au bon moment, sans le noyer d’informations. Avec l’Intelligence Artificielle, il est tentant de “faire naturel”. Or, la voix “naturelle” n’est pas toujours la voix la plus efficace. L’objectif est une conversation utile, pas une imitation humaine.
Liste de variantes A/B fréquentes qui améliorent l’Automatisation sans rigidifier
Pour cadrer l’idéation, voici une liste de tests qui ont du sens opérationnel et qui se déploient rapidement :
- Changer une question ouverte en question à choix restreint (“plutôt mardi ou mercredi ?”) pour augmenter le Taux de Conversion.
- Ajouter une phrase de réassurance (“Cela prend moins de 30 secondes”) pour réduire l’abandon.
- Déplacer une confirmation plus tôt (“D’accord, intervention à Lyon 3, c’est bien cela ?”) pour éviter les erreurs en fin de parcours.
- Tester deux styles de relance après silence (relance courte vs relance guidée) afin d’améliorer l’Interaction Vocale.
- Modifier l’ordre des champs (ville avant rue) selon les habitudes locales et le niveau de bruit.
- Tester deux stratégies d’escalade (transfert immédiat vs collecte minimale avant transfert) pour protéger l’Expérience Utilisateur.
Ces tests paraissent simples, mais ils doivent rester cohérents avec le modèle de compréhension. Si la NLU a été entraînée à détecter des réponses libres sur les créneaux, passer à des choix fermés peut améliorer la fiabilité de l’extraction. Dans ce cas, l’Automatisation progresse non pas grâce à une “meilleure IA”, mais grâce à un meilleur design de dialogue. L’insight final : sur la voix, l’art consiste à poser la bonne question, pas à traiter n’importe quelle réponse.
Découvrir AirAgent · Démo personnalisée offerte
Après avoir conçu des variantes, l’enjeu devient de les déployer proprement, en maîtrisant les biais et les effets de bord sur les segments d’appelants.
Analyse de Données et biais : sécuriser l’A/B Testing sur un Callbot en production
Un test A/B qui n’est pas protégé contre les biais peut pousser à de mauvaises décisions, même avec de “beaux” chiffres. Sur un Callbot, les biais sont parfois plus insidieux que sur le web, car les conditions audio changent en continu. Un lundi matin de pluie peut concentrer des appels depuis la voiture, avec davantage de bruit. Une campagne radio peut amener des prospects qui parlent plus vite. Si une variante reçoit davantage d’appels “faciles”, elle semblera gagnante sans l’être réellement.
La première barrière est la randomisation réelle. Il faut s’assurer que la répartition A/B se fait au niveau de l’appel, et idéalement au niveau de l’appelant (pour éviter qu’une même personne tombe sur A puis B et “apprenne” le parcours). Ensuite, la segmentation est indispensable : comparer les variantes globalement est utile, mais insuffisant. “Atelier Nova” a découvert qu’une variante plus directive augmentait le Taux de Conversion sur les appels de journée, mais le diminuait le soir, quand les appelants étaient plus pressés et demandaient un transfert rapide. La décision la plus rentable a donc été de personnaliser la stratégie selon le créneau horaire.
La qualité de transcription (ASR) est un autre facteur. Une variante qui incite à répondre par des phrases longues peut réduire la précision de reconnaissance, surtout sur des réseaux mobiles instables. Une approche méthodique consiste à monitorer le taux de mots inconnus, les répétitions, et les demandes de reformulation. Ces indicateurs ne sont pas des “vanity metrics” : ils expliquent pourquoi une variante convertit moins. L’Analyse de Données doit donc relier les signaux techniques (taux d’erreur) aux résultats métier (conversion, escalade).
Encadré “À retenir” : ce qui rend un test A/B crédible sur l’Interaction Vocale
À retenir : un test est crédible quand la différence de performance s’observe sur une période suffisamment stable, quand la population est comparable, et quand l’écart est expliqué par un mécanisme conversationnel identifiable. Sans mécanisme, le “gagnant” reste fragile.
Il est aussi utile d’éviter le piège de l’optimisation locale. Un embranchement peut sembler amélioré (moins d’abandon), tout en dégradant l’étape suivante (plus d’erreurs d’adresse). Pour réduire ce risque, il faut suivre une métrique primaire et une métrique de garde-fou, comme la satisfaction ou le taux de transfert. L’insight final : l’Optimisation est durable quand elle gagne sans casser la confiance.
Une fois la discipline de mesure en place, la question se déplace vers l’organisation : comment industrialiser ces cycles sans immobiliser les équipes, ni multiplier les versions ingérables.
Industrialiser l’Optimisation : gouvernance, cycles d’Automatisation et Conseil d’expert
Un programme d’A/B Testing réussi ne repose pas sur un “coup” ponctuel, mais sur un rythme. Les organisations les plus efficaces instaurent un cycle court : identifier une friction, formuler une hypothèse, lancer un test, analyser, puis standardiser. Dans “Atelier Nova”, la bascule a eu lieu quand les équipes ont arrêté de débattre des formulations pendant des heures. À la place, elles ont établi une règle : toute discussion doit se terminer par une hypothèse testable et un critère de décision.
La gouvernance compte autant que la technologie. Qui a le droit de lancer un test ? Qui valide un changement de script ? Qui surveille la conformité et la qualité (mentions légales, consentement, enregistrement) ? Sans ce cadre, l’Automatisation progresse, mais la cohérence se dégrade : l’appelant a l’impression de parler à plusieurs assistants différents selon les jours. L’enjeu est donc de créer une bibliothèque de “patterns” conversationnels validés : salutations, confirmations, relances, escalades, et clôtures.
Un point décisif concerne la collaboration entre relation client et technique. Le design de dialogue relève du métier, mais dépend de contraintes de compréhension, de latence et d’intégration CRM. Quand ces équipes travaillent en silo, l’Expérience Utilisateur se fragilise. À l’inverse, quand elles partagent un tableau de bord commun, les décisions deviennent rapides : une baisse du Taux de Conversion se relie immédiatement à une étape, puis à une version.
Conseil d’expert : bâtir un “pipeline” de tests sans épuiser les équipes
Conseil d’expert : maintenir en permanence trois niveaux de travail. D’abord des tests “rapides” sur des prompts (faible risque, déploiement immédiat). Ensuite des tests “structurels” sur l’ordre des étapes (risque moyen, forte valeur). Enfin des améliorations “modèle” sur la compréhension (plus long, mais essentiel). Cette approche évite de bloquer l’optimisation sur un seul type de chantier.
Dans ce cadre, une solution qui facilite le versioning des scripts, la répartition du trafic, et le reporting par intention accélère mécaniquement les résultats. L’insight final : l’industrialisation transforme l’A/B Testing d’une pratique occasionnelle en avantage compétitif.
Tester AirAgent gratuitement · Sans engagement
Quels Scénarios Conversationnels tester en priorité sur un callbot ?
Les priorités sont les moments où l’appelant hésite ou abandonne : collecte d’informations (adresse, numéro de dossier), choix de créneau, confirmation finale, et relance après silence. Un bon point de départ consiste à cibler une intention à fort volume et forte valeur, puis à tester des micro-variantes de formulation et de guidage pour améliorer le Taux de Conversion sans augmenter les transferts vers un agent.
Comment éviter que l’A/B Testing dégrade l’Expérience Utilisateur ?
Deux mécanismes protègent l’Expérience Utilisateur : définir une métrique de garde-fou (satisfaction, taux d’escalade, taux d’abandon) et limiter les changements à une variable à la fois. Sur l’Interaction Vocale, il est aussi recommandé de tester d’abord sur un segment contrôlé (par exemple un créneau horaire), puis d’étendre si les résultats restent stables.
Quelle différence entre Optimisation de script et amélioration du modèle d’Intelligence Artificielle ?
L’optimisation de script ajuste le dialogue (questions, confirmations, relances) pour guider l’appelant et réduire l’ambiguïté. L’amélioration du modèle concerne la compréhension (ASR/NLU) et la capacité à reconnaître plus de formulations. En pratique, une bonne Automatisation combine les deux : un script clair réduit les erreurs de compréhension, tandis qu’un modèle robuste accepte davantage de variations naturelles.
Combien de temps faut-il pour obtenir des résultats fiables en A/B Testing sur un Callbot ?
Cela dépend du volume d’appels et de la variabilité des situations (bruit, accents, sources d’appels). Un repère opérationnel consiste à attendre un volume suffisant sur l’intention testée pour que l’écart soit stable, puis à valider sur une seconde période. L’Analyse de Données doit systématiquement segmenter par motif d’appel et par contexte (heures de pointe, campagnes) pour éviter les conclusions hâtives.


